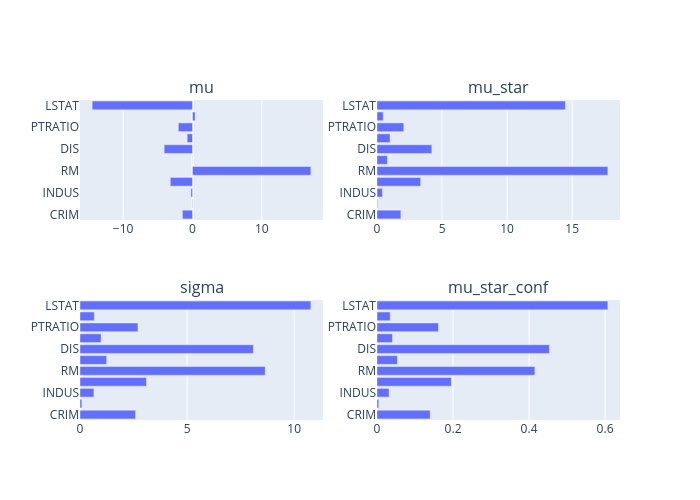
Morris sensitivity analysis
Morris sensitivity analysis for tabular data based on the SALib. If using this explainer, please cite the package: https://github.com/SALib/SALib. This explainer only supports continuous-valued features.
[1]:
# This default renderer is used for sphinx docs only. Please delete this cell in IPython.
import plotly.io as pio
pio.renderers.default = "png"
[2]:
import numpy as np
import pandas as pd
import sklearn
import sklearn.ensemble
from sklearn.datasets import load_boston
from omnixai.data.tabular import Tabular
from omnixai.preprocessing.base import Identity
from omnixai.preprocessing.tabular import TabularTransform
from omnixai.explainers.tabular import SensitivityAnalysisTabular
We recommend using Tabular to represent a tabular dataset, which can be constructed from a pandas dataframe or a numpy array. To create a Tabular instance given a pandas dataframe, one needs to specify the dataframe, the categorical feature names (if exists) and the target/label column name (if exists).
[3]:
boston = load_boston()
df = pd.DataFrame(
np.concatenate([boston.data, boston.target.reshape((-1, 1))], axis=1),
columns=list(boston.feature_names) + ['target'])
# Remove categorical features
df = df.drop(columns=[boston.feature_names[i] for i in [3, 8]])
tabular_data = Tabular(df, target_column='target')
We train a random forest model for this regression task.
[4]:
transformer = TabularTransform(
target_transform=Identity()
).fit(tabular_data)
x = transformer.transform(tabular_data)
x_train, x_test, y_train, y_test = \
sklearn.model_selection.train_test_split(x[:, :-1], x[:, -1], train_size=0.80)
print('Training data shape: {}'.format(x_train.shape))
print('Test data shape: {}'.format(x_test.shape))
rf = sklearn.ensemble.RandomForestRegressor(n_estimators=1000)
rf.fit(x_train, y_train)
print('Random Forest MSError', np.mean((rf.predict(x_test) - y_test) ** 2))
Training data shape: (404, 11)
Test data shape: (102, 11)
Random Forest MSError 10.215751067843145
To initialize a sensitivity analyzer, we need to set:
training_data: The data used to initialize the explainer.training_datacan be the training dataset for training the machine learning model. If the training dataset is too large,training_datacan be a subset of it by applyingomnixai.sampler.tabular.Sampler.subsample.predict_function: The prediction function corresponding to the model.
[5]:
predict_function = lambda z: rf.predict(transformer.transform(z))
explainer = SensitivityAnalysisTabular(
training_data=tabular_data,
predict_function=predict_function,
)
SensitivityAnalysisTabular generates global explanations by calling explain. ipython_plot shows the generated explanations in IPython.
[6]:
explanations = explainer.explain()
explanations.ipython_plot()