Layers
Introduction
The Substrate SDK uses a layered architecture to provide a clean separation between the public API, internal abstractions, and provider-specific implementations. This architecture enables:
- A consistent, substrate-agnostic experience for end users
- Easy addition of new cloud providers
- Clear separation of concerns
- Maintainable and testable code
Components
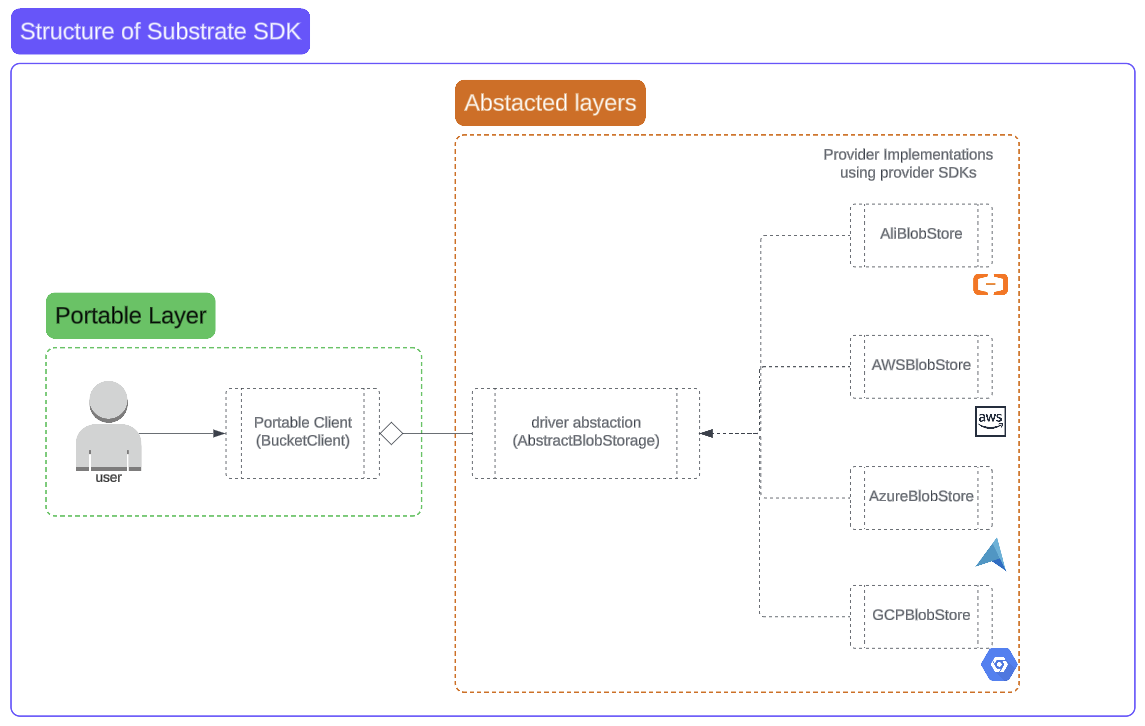
The architecture consists of three main layers:
- Portable Layer (Top) - The public-facing API that users interact with
- Driver Layer (Middle) - The abstraction layer that defines common interfaces
- Provider Layer (Bottom) - The implementation layer for specific cloud providers
Portable Layer
The portable layer is the most important and front-facing layer for end users. End users should mostly interact with the portable Layer to make cloud service calls. The portable Layer should expose all necessary functions/APIs for the end user. For example, for a blobstore service, it can expose methods like upload, download, delete, etc., through the portable Layer.
Characteristics of an ideal portable Layer:
- The portable Layer should be substrate-agnostic, containing no substrate-specific logic. It should offer a substrate-agnostic experience for the end user.
- The portable Layer should accept the substrate(provider) value from the end user and initiate the appropriate session on that substrate. (We might consider that empty provider will pick whatever provider it finds first in the classpath, if required).
- The portable Layer should allow users to provide substrate-agnostic inputs such as region name, credentials through a credentials provider defined in Substrate SDK, bucket name (for blob services), etc.
- The portable Layer should only expose functions that are supported across all substrates. It should not support or expose features that work on one substrate but not on others.
- The portable Layer should strive to provide the best experience for the end user, requiring as little information as possible.
Example usage of the portable Layer for blob storage and uploading the blob:
// hardcodes for illustration purposes values should be outside of the service code
String substrate = "aws"
String region = "us-east-1"
// Setting up session credentials -
// these are optional and ideally in prod, this is not required
// since the k8s pods are set with default credentials and Substrate SDK
// uses the default credentials in that case.
StsCredentials credentials = new StsCredentials(
"accessKeyId",
"accessKeySecret",
"sessionToken");
CredentialsOverrider credsOverrider = new CredentialsOverrider
.Builder(CredentialsType.SESSION).withSessionCredentials(credentials).build();
// Initiate the substrate agnostic BucketClient
BucketClient client = BucketClient.builder(substrate)
.withBucket("chameleon-java")
.withRegion(region)
.withCredentialsOverrider(credsOverrider).build();
// Prepare the substrate agnostic UploadRequest
UploadRequest uploadRequest = new UploadRequest.Builder()
.withKey("bucket-path/chameleon.jpg")
// Upload the content
UploadResponse response = client.upload(uploadRequest, "dummy-content");
The above example demonstrates that the end user wants to open the client for the blob storage in the AWS substrate to the bucket “chameleon-java” in the region “us-east-1”. The client is used to upload/write the blob in the bucket.
In this example, the portable fulfills all the requirements as discussed above:
- There is no substrate specific logic exposed on the portable Layer. From the code block, there is no substrate specific exposure and this logic works in the same manner for other substrates by just providing a different substrate value.
- portable Layer forces the client the provide a substrate value, it doesn’t assume or interpret the substrate based on the runtime.
- It provides a way to supply inputs to open the session in a substrate agnostic manner.
- It asks the minimum amount of information from the end user without knowing the internals of the SDK.
Driver Layer
The driver layer is a layer behind the portable Layer which defines the abstract functions and implementations for each substrate/provider. The driver layer can also include wrapper logic on top of abstract functions to further simplify portable Layer.
Structure
The basic structure of abstract Blob Store looks like this which defines some variables required for the provider implementation such as region and the provider id:
public abstract class AbstracBlobtore {
protected final String providerId;
protected final String region;
protected final String bucket;
// Abstract methods for substrate-specific implementations
protected abstract UploadResponse doUpload(UploadRequest uploadRequest);
protected abstract DownloadResponse doDownload(DownloadRequest downloadRequest);
protected abstract void doDelete(String key);
}
Why do need a separate driver layer?
While it’s possible to achieve the abstraction of service capabilities without this driver layer and instead make the portable layer an abstract class, there are numerous benefits to keeping the portable layer separate. These benefits include:
Separation of concerns:
Abstract classes deal with internal code of SDK and abstract methods for providers to implement where as portable Layer or client is all about external facing code. We can keep the portable Layer light weight and to the point. Driver abstraction consist of:
- Common methods for logic which applies to all providers
- Abstract methods to be implemented by providers
Prevention of leaky abstractions:
Having a separate portable Layer prevents the leaky abstractions because the client doesn’t have to deal with or access the driver layer which might expose some internals.
Maintainability:
Changing the internal implementations are comparatively safe without breaking portable Layer contracts.
Testing:
End users have simple portable layer for mocks and testing.
Example:
For instance, the upload method in BucketClient have multiple methods in the backend, such as validateContent to validate if the content is in the right format which is common for all providers. This validateContent method should be internal and not exposed to end users, therefore it can be part of driver layer and keep the BucketClient purely public.
Secondly, if we have a prepContent abstraction function in driver which should be implemented by all the provider implementations to prepareContent for specific substrate. Now, let’s say each substrate appends the content with some prefix bytes which are substrate specific. So the upload method is executed as follow behind the scenes:
public UploadResponse upload(UploadRequest uploadRequest) {
validation(); <- this is common validation for all substrates
prepContent(); <- this is provider specific prep content
doUpload(); this is provider specific upload of the content
}
Basically we might have several methods which the end user doesn’t care about and should be completely abstracted from the users. These functions should be placed in driver layer, keeping the portable layer purely public and sanitized.
Provider Layer
Provider layer implements the driver layer for each substrate. Provider layer is for each provider or substrate which powers the API calls from the end users to make substrate specific calls. In the below code example: AWSBlobStore is the provider for blob/blobstore for AWS substrate and implements all the abstract functions in the AWS substrate.
public class AWSBlobStore extends AbstractBlobStore {
S3Client s3Client;
public AWSBlobStore(Builder builder) {
s3Client = ... // code logic to build the s3Client by information from builder
}
@Override
protected void doUploadFile(String key, String filePath) {
Map<String, String> metadata = new HashMap<>();
PutObjectRequest putOb = PutObjectRequest.builder()
.bucket(this.bucketName)
.key(key)
.metadata(metadata)
.build();
s3Client.putObject(putOb, RequestBody.fromFile(new File(filePath)));
log.info("Successfully placed object" + " into bucket " + bucketName);
}
@Override
public Builder builder() {
return new Builder();
}
public static class Builder extends AbstractBlobStore.Builder<AwsBlobStore> {
public Builder() {
providerId("aws");
}
@Override
public AwsBlobStore build() {
return new AwsBlobStore(this);
}
...
}
}
Best Practices
- Keep the Portable Layer Clean
- Only expose substrate-agnostic APIs
- Validate inputs before passing to driver layer
- Handle common error cases
- Driver Layer Design
- Define clear interfaces
- Include common validation logic
- Provide default implementations where possible
- Document expected behavior
- Provider Implementation
- Follow the driver layer contract strictly
- Handle provider-specific edge cases
- Implement proper error handling
- Add provider-specific logging
Common Pitfalls
- Leaky Abstractions
- Avoid exposing provider-specific types in the portable layer
- Don’t let provider-specific exceptions bubble up
- Keep provider-specific configuration internal
- Inconsistent Behavior
- Ensure all providers implement the same behavior
- Handle edge cases consistently
- Document any provider-specific limitations
- Performance Issues
- Avoid unnecessary abstraction layers
- Cache provider clients when possible
- Use efficient data structures